I recently wrote a little application to convert pages from a PDF to plain text. The GUI portion of the application looks like this:
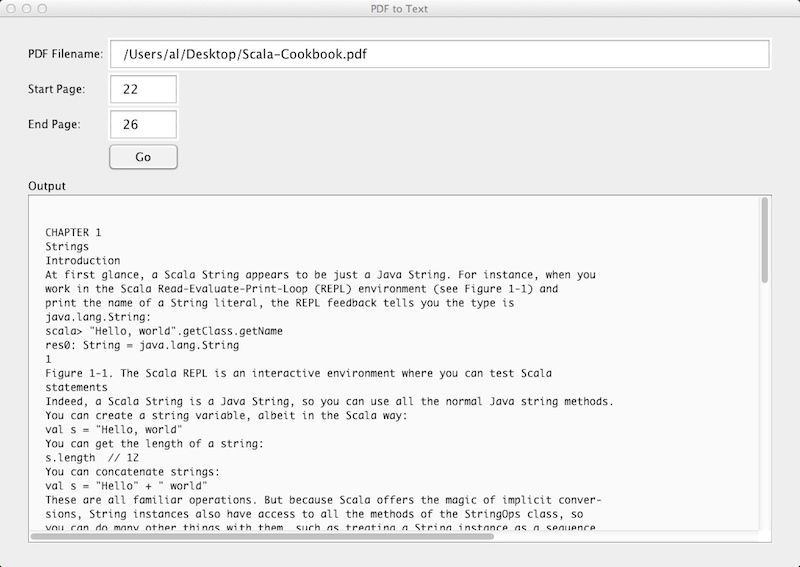
As you can see, the application just needs the name of a PDF file to convert, along with the page you want to start at and the page you want to end at. There are several ways I could make the application more convenient to use, but since I don't plan to use it that often, I can deal with its limitations.
In my Github project you’ll find a shell script to compile the application into a native Mac OS X application. (You can also compile the application to a single Jar file that you can use on Linux or Windows.)
A "PDF to plain text" Scala shell script
I’ve also written a Scala shell script to do the same thing (convert the pages from a PDF file to plain text). I named the Scala shell script pdftotext.sh, and it currently looks like this:
#!/bin/sh
exec scala -savecompiled -classpath "lib/pdfbox-app-1.8.7.jar:lib/commons-io-2.4.jar" "$0" "$@"
!#
import java.io._
import org.apache.pdfbox.pdmodel.PDDocument
import org.apache.pdfbox.util.PDFTextStripper
object PdfToText {
System.setProperty("java.awt.headless", "true")
def main(args: Array[String]) {
if (args.length != 3) printUsageAndExit
val startPage = args(0).toInt
val endPage = args(1).toInt
val filename = args(2)
// sanity check
if (startPage > endPage) printUsageAndExit
println(getTextFromPdf(startPage, endPage, filename))
}
def printUsageAndExit {
println("")
println("Usage: pdftotext startPage endPage filename")
println(" (endPage must be >= startPage)")
System.exit(1)
}
def getTextFromPdf(startPage: Int, endPage: Int, filename: String): Option[String] = {
try {
val pdf = PDDocument.load(new File(filename))
val stripper = new PDFTextStripper
stripper.setStartPage(startPage)
stripper.setEndPage(endPage)
Some(stripper.getText(pdf))
} catch {
case t: Throwable =>
t.printStackTrace
None
}
}
}
PdfToText.main(args)
This script can be run like this:
$ pdftotext.sh 100 105 /Users/al/Desktop/Scala-Cookbook.pdf
Like the GUI, I could also make this script a little more convenient for the end user, but that’s the way it works today.
As a side note, if you wanted to see (a) how to include Jar files in a Scala shell script, (b) how to read command line arguments in a Scala shell script, or (c) how to precompile a Scala shell script, I hope that code is helpful.
Libraries and source code
The source code for this project is written in Scala, and the GUI uses Akka actors to help keep the GUI from coming to a screaming halt when the PDF file is read. Also very importantly, it uses the Apache PDFBox library to read PDF files and extract their text.
The source code for the GUI and shell script are open source, and you can find it here on Github.
Warning
The code assumes that the PDF you’re reading has only one column per page. I have no idea what will happen if you try to extract content from PDF files that have multiple columns. I think there are methods in the PDFBox library to account for that, but since I haven’t needed it, I haven’t looked at it.
Summary
In summary, if you are looking for some code to convert a PDF to plain text, I hope you find this useful.
books by alvin
 |
 |
 |
 |