(Note: I originally wrote this article in 2010 or 2011, but I tend to like articles that I wrote while in the midst of a ton of design, programming, and testing work, and this is one of them.)
| this post is sponsored by my books: | |||

#1 New Release |

FP Best Seller |

Learn Scala 3 |

Learn FP Fast |
Over the last 18 months I've been working with a 24x7 manufacturing group, and no matter what I say, they always have the same two requests/demands:
- The software system must not fail, and
- If it does fail for some reason, it needs to be able to recover properly from the failure.
Simply put, (a) the machines must keep moving, and (b) nobody wants the phone call in the middle of the night when the machines stop moving.
As you can imagine, the first request can be hard to solve if taken to extremes. In short, it's hard to write perfect software, especially on ultra-tight budgets. As long as budgets are tight, and domain experts can't give you all of the requirements, there will be bugs. For that first requirement I can test like crazy given the known requirements, but as for those unknowns ...
For the purposes of this article, that second request is what I'm here to write about today. I have learned that you can create self healing software in a cost-effective manner, and I'd like to share what I've learned here.
Supporting "software self healing"
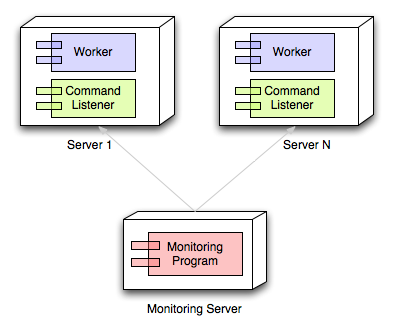
You need at least three components in a software self healing environment:
- The worker program that you develop (the one that normally runs without a problem).
- A monitoring program that monitors your worker.
- A third program, installed with the worker, that is capable of restarting the worker.
These components are shown roughly in the following image, where your worker programs and command listeners are installed on any number of remote servers, and they are monitored and managed from a monitoring server.
Let me describe each of these components in a little more detail.
Self healing component #1: Your worker program
Here lately my worker programs have been standalone (headless) programs that run on or more servers, and perform a dedicated task. For example, I recently developed a fleet of "FTP file movers": programs that take events from FTP servers and move files from the FTP servers into internal workflows. These file movers are written in Java, and have been deployed on a series of Linux servers.
The things I call "worker programs" can also be other things, like web services or web applications. I'm going to assume you know what these are, so I'm not going to provide any examples of these.
The important thing about these worker programs is that they support a minimal set of methods that can be called remotely by a monitoring application. As a minimum, these programs must support the following method call (or "interface", if you prefer):
- Support a
status()query
Beyond that, if possible, it is also helpful if they can also accept the following commands, which can be invoked remotely:
- A
stop()command - A
restart()command
| this post is sponsored by my books: | |||
|
#1 New Release |
FP Best Seller |
Learn Scala 3 |
Learn FP Fast |
I won't get into all of the details of how to support these remote queries, other than to say that you have an incredible variety of options these days, including:
- Java RMI
- Java JMX
- SOAP web service calls
- REST web service calls
- Other
I'm sure there are many more ways of supporting this functionality, but those first four are plenty for me. In the rest of this document I will show how to use Option #4, REST service calls, as I think they are the easiest to implement.
Next: Part 2 of this article, the monitoring program.
books by alvin
|
|
|
|