“Functional programming is often regarded as the best-kept secret of scientific modelers, mathematicians, artificial intelligence researchers, financial institutions, graphic designers, CPU designers, compiler programmers, and telecommunications engineers.”
As I write about the benefits of functional programming in this chapter, I need to separate my answers into two parts. First, there are the benefits of functional programming in general. Second, there are more specific benefits that come from using functional programming in Scala. I’ll look at both of these in these chapter.
| this post is sponsored by my books: | |||

#1 New Release |

FP Best Seller |

Learn Scala 3 |

Learn FP Fast |
Benefits of functional programming in general
Experienced functional programmers make the following claims about functional programming, regardless of the language they use:
- Pure functions are easier to reason about
- Testing is easier, and pure functions lend themselves well to techniques like property-based testing
- Debugging is easier
- Programs are more bulletproof
- Programs are written at a higher level, and are therefore easier to comprehend
- Function signatures are more meaningful
- Parallel/concurrent programming is easier
I’ll discuss these benefits in this chapter, and then offer further proof of them as you go through this book.
Benefits of functional programming in Scala
On top of those benefits of functional programming in general, Scala/FP offers these additional benefits:
- Being able to (a) treat functions as values and (b) use anonymous functions makes code more concise, and still readable
- Scala syntax generally makes function signatures easy to read
- The Scala collections’ classes have a very functional API
- Scala runs on the JVM, so you can still use the wealth of JVM-based libraries and tools with your Scala/FP applications
In the rest of this chapter I’ll explore each of these benefits.
1) Pure functions are easier to reason about
The book, Real World Haskell, states, “Purity makes the job of understanding code easier.” I’ve found this to be true for a variety of reasons.
First, pure functions are easier to reason about because you know that they can’t do certain things, such as talk to the outside world, have hidden inputs, or modify hidden state. Because of this, you’re guaranteed that their function signatures tell you (a) exactly what’s going into each function, and (b) coming out of each function.
In his book, Clean Code, Robert Martin writes:
“The ratio of time spent reading (code) versus writing is well over 10 to 1 ... (therefore) making it easy to read makes it easier to write.”
I suspect that this ratio is lower with FP. Because pure functions are easier to reason about:
- I spend less time “reading” them.
- I can keep fewer details in my brain for every function that I read.
This is what functional programmers refer to as “a higher level of abstraction.”
Because I can read pure functions faster and use less brain memory per function, I can keep more overall logic in my brain at one time.
Several other resources support these statements. The book Masterminds of Programming includes this quote: “As David Balaban (from Amgen, Inc.) puts it, ‘FP shortens the brain-to-code gap, and that is more important than anything else.’”
In the book, Practical Common Lisp, Peter Seibel writes:
“Consequently, a Common Lisp program tends to provide a much clearer mapping between your ideas about how the program works and the code you actually write. Your ideas aren't obscured by boilerplate code and endlessly repeated idioms. This makes your code easier to maintain because you don’t have to wade through reams of code every time you need to make a change.”
Although he’s writing about Lisp, the same logic applies to writing pure functions.
Another way that pure functions make code easier to reason about won’t be apparent when you’re first getting started. It turns out that what really happens in FP applications is that (a) you write as much of the code as you can in a functional style, and then (b) you have other functions that reach out and interact with files, databases, web services, UIs, and so on — everything in the outside world.
The concept is that you have a “Pure Function” core, surrounded by impure functions that interact with the outside world:
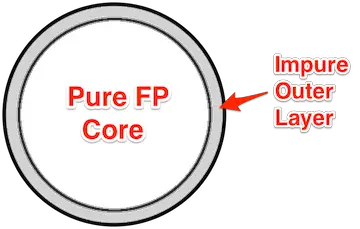
Given this design, a great thing about Haskell in particular is that it provides a clean separation between pure and impure functions — so clean that you can tell by looking at a function’s signature whether it is pure or impure. I discuss this more in the coming lessons, but for now, just know that developers have built libraries to bring this same benefit to Scala/FP applications.
2) Testing is easier, and pure functions lend themselves well to techniques like property-based testing
As I show in the Scala Cookbook, it’s easier to test pure functions because you don’t have to worry about them dealing with hidden state and side effects. What this means is that in imperative code you may have a method like this:
def doSomethingHidden(o: Order, p: Pizza): Unit ...
You can’t tell much about what that method does by looking at its signature, but — because it returns nothing (Unit) — presumably it (a) modifies those variables, (b) changes some hidden state, or (c) interacts with the outside world.
When methods modify hidden state, you end up having to write long test code like this:
test("test hidden stuff that has side effects") {
setUpPizzaState(p)
setUpOrderState(o, p)
doSomethingHidden(o, p)
val result = getTheSideEffectFromThatMethod()
assertEquals(result, expectedResult)
}
In FP you can’t have code like that, so testing is simpler, like this:
test("test obvious stuff") {
val result = doSomethingObvious(x, y, z)
test(result, expectedResult)
}
Proofs
Beyond making unit testing easier, because functional code is like algebra it also makes it easier to use a form of testing known as property-based testing.
I write much more about this in the lesson on using ScalaCheck, but the main point is that because the outputs of your functions depend only on their inputs, you can define “properties” of your functions, and then ScalaCheck “attacks” your functions with a large range of inputs.
With a few minor edits, the property-based testing page on the ScalaTest website states:
“... a property is a high-level specification of behavior that should hold for a range of data points. For example, a property might state, ‘The size of a list returned from a method should always be greater than or equal to the size of the list passed to that method.’ This property should hold no matter what list is passed.”
“The difference between a traditional unit test and a property is that unit tests traditionally verify behavior based on specific data points ... for example, a unit test might pass three or four specific lists to a method that takes a list and check that the results are as expected. A property, by contrast, describes at a high level the preconditions of the method under test and specifies some aspect of the result that should hold no matter what valid list is passed.”
3) Debugging is easier
Because pure functions depend only on their input parameters to produce their output, debugging applications written with pure functions is easier. Of course it’s possible to still make a mistake when you write a pure function, but once you have a stack trace or debug output, all you have to do is follow the values to see what went wrong. Because the functions are pure, you don’t have to worry about what’s going on in the rest of the application, you just have to know the inputs that were given to the pure function that failed.
In Masterminds of Programming, Paul Hudak, a co-creator of the Haskell language, states, “I’ve always felt that the ‘execution trace’ method of debugging in imperative languages was broken ... in all my years of Haskell programming, I have never in fact used Buddha, or GHC’s debugger, or any debugger at all ... I find that testing works just fine; test small pieces of code using QuickCheck or a similar tool to make things more rigorous, and then — the key step — simply study the code to see why things don’t work the way I expect them to. I suspect that a lot of people program similarly, otherwise there would be a lot more research on Haskell debuggers ...”
ScalaCheck is a property-based testing framework for Scala that was inspired by Haskell’s QuickCheck.
4) Programs are more bulletproof
People that are smarter than I am can make the mathematical argument that complete FP applications are more bulletproof than other applications. Because there are fewer “moving parts” — mutatable variables and hidden state — in FP applications, mathematically speaking, the overall application is less complex. This is true for simple applications, and the gap gets larger in parallel and concurrent programming (as you’ll see in a later section in this chapter).
The way I can explain this is to share an example of my own bad code. A few years ago I started writing a football game for Android devices (American football), and it has a lot of state to consider. On every play there is state like this:
- What quarter is it?
- How much time is left in the quarter?
- What is the score?
- What down is it?
- What distance is needed to make a first down?
- Much more ...
Here’s a small sample of the now-embarrassing public static fields I globally mutate in that application:
// stats for human
public static int numRunsByHuman = 0;
public static int numPassAttemptsByHuman = 0;
public static int numPassCompletionsByHuman = 0;
public static int numInterceptionsThrownByHuman = 0;
public static int numRunningYardsByHuman = 0;
public static int numPassingYardsByHuman = 0;
public static int numFumblesByHuman = 0;
public static int numFirstDownRunsByHuman = 0;
public static int numFirstDownPassesByHuman = 0;
When I wrote this code I thought, “I’ve written Java Swing (GUI) code since the 1990s, and Android code for a few years. I’m working by myself on this, I don’t have to worry about team communication. I know what I’m doing, what could possibly go wrong?”
In short, although a football game is pretty simple compared to a business application, it still has a lot of “state” that you have to maintain. And when you’re mutating that global state from several different places, well, it turns out that sometimes the computer gets an extra play, sometimes time doesn’t run off the clock, etc.
Skipping all of my imperative state-related bugs ... once I learned how to handle state in FP applications, I gave up trying to fix those bugs, and I’m now rewriting the core of the application in an FP style.
As you’ll see in this book, the solution to this problem is to pass the state around as a value, such as a case class or
Map. In this case I might call itGameState, and it would have fields likequarter,timeRemaining,down, etc.
A second argument about FP applications being more bulletproof is that because they are built from all of these little pure functions that are known to work extraordinarily well, the overall application itself must be safer. For instance, if 80% of the application is written with well-tested pure functions, you can be very confident in that code; you know that it will never have the mutable state bugs like the ones in my football game. (And if somehow it does, the problem is easier to find and fix.)
As an analogy, one time I had a house built, and I remember that the builder was very careful about the 2x4’s that were used to build the framework of the house. He’d line them up and then say, “You do not want that 2x4 in your house,” and he would be pick up a bent or cracked 2x4 and throw it off to the side. In the same way that he was trying to build the framework of the house with wood that was clearly the best, we use pure functions to build the best possible core of our applications.
Yes, I know that programmers don’t like it when I compare building a house to writing an application. But some analogies do fit.
5) Programs are written at a higher level, and are therefore easier to comprehend
In the same way that pure functions are easier to reason about, overall FP applications are also easier to reason about. For example, I find that my FP code is more concise than my imperative and OOP code, and it’s also still very readable. In fact, I think it’s more readable than my older code.
Wikipedia states, “Imperative programming is a programming paradigm that uses statements that change a program's state.”
Some of the features that make FP code more concise and still readable are:
- The ability to treat functions as values
- The ability to pass those values into other functions
- Being able to write small snippets of code as anonymous functions
- Not having to create deep hierarchies of classes (that sometimes feel “artifical”)
- Most FP languages are “low ceremony” languages, meaning that they require less boilerplate code than other languages
If you want to see what I mean by FP languages being “low ceremony,” here’s a good example of OCaml, and this page shows examples of Haskell’s syntax.
In my experience, when I write Scala/FP code that I’m comfortable with today, I have always been able to read it at a later time. And as I mentioned when writing about the benefits of pure functions, “concise and readable” means that I can keep more code in my head at one time.
6) Pure function signatures are meaningful
When learning FP, another big “lightbulb going on over my head” moment came when I saw that my function signatures were suddenly much more meaningful than my imperative and OOP method signatures.
Because non-FP methods can have side effects — which are essentially hidden inputs and outputs of those methods — their function signatures often don’t mean that much. For example, what do you think this imperative method does:
def doSomething(): Unit { code here ...
The correct answer is, “Who knows?” Because it takes no input parameters and returns nothing, there’s no way to guess from the signature what this method does.
In contrast, because pure functions depend only on their input parameters to produce their output, their function signatures are extremely meaningful — a contract, even.
I write more about this in the upcoming lesson, “Pure Functions Tell All.”
7) Parallel/concurrent programming is easier
While writing parallel and concurrent applications is considered a “killer app” that helped spur renewed interest in FP, I have written my parallel/concurrent apps (like Sarah) primarily using Akka Actors and Scala Futures, so I can only speak about them: they’re awesome tools. I wrote about them in the Scala Cookbook and on my website (alvinalexander.com), so please search those resources for “actors” and “futures” to find examples.
Therefore, to support the claims that FP is a great tool for writing parallel/concurrent applications, I’m going to include quotes here from other resources. As you’ll see, the recurring theme in these quotes is, “Because FP only has immutable values, you can’t possibly have the race conditions that are so difficult to deal with in imperative code.”
The first quote comes from an article titled, “Functional Programming for the Rest of Us,”:
“A functional program is ready for concurrency without any further modifications. You never have to worry about deadlocks and race conditions because you don’t need to use locks. No piece of data in a functional program is modified twice by the same thread, let alone by two different threads. That means you can easily add threads without ever giving conventional problems that plague concurrency applications a second thought.”
The author goes on to add the information shown in this image:

The Clojure.org website adds these statements about how Clojure and FP help with concurrency:

Page 17 of the book, Haskell, the Craft of Functional Programming, states, “Haskell programs are easy to parallelize, and to run efficiently on multicore hardware, because there is no state to be shared between different threads.”
In this article on the ibm.com website, Neal Ford states, “Immutable objects are also automatically thread-safe and have no synchronization issues. They can also never exist in unknown or undesirable state because of an exception.”
In the pragprom.com article, Functional Programming Basics, famous programmer Robert C. Martin extrapolates from four cores to a future with 131,072 processors when he writes:
“Honestly, we programmers can barely get two Java threads to cooperate ... Clearly, if the value of a memory location, once initialized, does not change during the course of a program execution, then there’s nothing for the 131072 processors to compete over. You don’t need semaphores if you don’t have side effects! You can’t have concurrent update problems if you don’t update! ... So that’s the big deal about functional languages; and it is one big fricking deal. There is a freight train barreling down the tracks towards us, with multi-core emblazoned on it; and you’d better be ready by the time it gets here.”
With a slight bit of editing, an article titled, The Downfall of Imperative Programming states:
“Did you notice that in the definition of a data race there’s always talk of mutation? Any number of threads may read a memory location without synchronization, but if even one of them mutates it, you have a race. And that is the downfall of imperative programming: Imperative programs will always be vulnerable to data races because they contain mutable variables.”
id Software co-founder and technical director John Carmack states:
“Programming in a functional style makes the state presented to your code explicit, which makes it much easier to reason about, and, in a completely pure system, makes thread race conditions impossible.”
Writing Erlang code is similar to using the Akka actors library in Scala. The Erlang equivalent to an Akka actor is a “process,” and in his book, Programming Erlang, Joe Armstrong writes:
“Processes share no data with other processes. This is the reason why we can easily distribute Erlang programs over multicores or networks.”
For a final quote, “The Trouble with Shared State” section on this medium.com article states, “In fact, if you’re using shared state and that state is reliant on sequences which vary depending on indeterministic factors, for all intents and purposes, the output is impossible to predict, and that means it’s impossible to properly test or fully understand. As Martin Odersky puts it:”
non-determinism = parallel processing + mutable state
The author follows that up with an understatement: “Program determinism is usually a desirable property in computing.”
8) Scala/FP benefit: The ability to treat functions as values
I’ve already written a little about higher-order functions (HOFs), and I write more about them later in this book, so I won’t belabor this point: the fact that Scala (a) lets you treat functions as values, (b) lets you pass functions around to other functions, and (c) lets you write concise anonymous functions, are all features that make Scala a better functional programming language than another language (such as Java) that does not have these features.
9) Scala/FP benefit: Syntax makes function signatures easy to read
In my opinion, the Scala method syntax is about as simple as you can make method signatures, especially signatures that support generic types. This simplicity usually makes method signatures easy to read.
For instance, it’s easy to tell that this method takes a String and returns an Int:
def foo(s: String): Int = ???
These days I prefer to use explicit return types on my methods, such as the Int in this example. I think that being explicit makes them easier to read later, when I’m in maintenance mode. And in an example like this, I don’t know how to make that method signature more clear.
If you prefer methods with implicit return types you can write that same method like this, which is also clear and concise:
def foo(s: String) = ???
Even when you need to use generic type parameters — which make any method harder to read — Scala method signatures are still fairly easy to read:
def foo[A, B](a: A): B = ???
It’s hard to make it much easier than that.
Occasionally I think that I’d like to get rid of the initial generic type declaration in the brackets — the [A, B] part — so the signature would look like this:
def foo(a: A): B = ???
While that’s more concise for simple type declarations, it would create an inconsistency when you need to use advanced generic type features such as bounds and variance, like this example I included in the Scala Cookbook:
def getOrElse[B >: A](default: => B): B = ???
Even with the initial brackets, the type signatures are still fairly easy to read. You can make the argument that declaring the generic types in brackets before the rest of the signature makes it clear to the reader that they are about to see those types in the remainder of the signature. For instance, when you read this function:
def foo[A, B](a: A): B = ???
you can imagine saying to yourself, “This is a function named foo ... its signature is going to use two generic types A and B, and then ...”
Given what generic types represent, I think that’s pretty clear.
10) Scala/FP benefit: The collections classes have a functional API
When I first came to Scala from Java, the Scala collections API was a real surprise. But, once I had that “Aha!” moment and realized how they work, I saw what a great benefit they are. Having all of those standard functional methods eliminates almost every need for custom for loops.
The important benefit of this is that these standard methods make my code more consistent and concise. These days I write almost 100% fewer custom for loops, and that’s good for me — and anyone who has to read my code.
11) Scala/FP benefit: Code runs on the JVM
Because the Scala compiler generates Java bytecode that runs on the JVM, and because Scala supports both FP and OOP models, you can still use all of those thousands of Java/JVM libraries that have been created in the last twenty years in your Scala/FP applications. Even if those libraries aren’t “Pure FP,” at least you can still use them without having to “reinvent the wheel” and write a new library from scratch.
In fact, not only can you use the wealth of existing JVM libraries, you can also use all of your favorite JVM tools in general:
- Build tools like Ant, Maven, Gradle, and SBT
- Test tools like JUnit, TestNG, mock frameworks
- Continuous integration tools
- Debugging and logging frameworks
- Profiling tools
- More ...
These libraries and tools are a great strength of the JVM. If you ask experienced FP developers why they are using Scala rather than Haskell or another FP language, “libraries, tools, and JVM” is the usual answer.
One more thing ...
On a personal note, a big early influence for me — before I knew about any of these benefits — was seeing people like Martin Odersky, Jonas Bonér, Bill Venners, and other leading Scala programmers use and promote an FP style. Because Scala supports both OOP and FP, it’s not like they had to sell anyone on FP in order to get us to use Scala. (As a former business owner, I feel like I’m always on the lookout for people who are trying to “sell” me something.)
I don’t know if they use FP 100% of the time, but what influenced me is that they started using FP and then they never said, “You know what? FP isn’t that good after all. I’m going back to an imperative style.”
In the 2016 version of Programming in Scala, Martin Odersky’s biography states, “He works on programming languages and systems, more specifically on the topic of how to combine object-oriented and functional programming.” Clearly FP is important to him (as is finding the best ways to merge FP and OOP concepts).
| this post is sponsored by my books: | |||
|
#1 New Release |
FP Best Seller |
Learn Scala 3 |
Learn FP Fast |
Summary
In summary, the benefits of “functional programming in general” are:
- Pure functions are easier to reason about
- Testing is easier, and pure functions lend themselves well to techniques like property-based testing
- Debugging is easier
- Programs are more bulletproof
- Programs are written at a higher level, and are therefore easier to comprehend
- Function signatures are more meaningful
- Parallel/concurrent programming is easier
On top of those benefits, “functional programming in Scala” offers these additional benefits:
- Being able to (a) treat functions as values and (b) use anonymous functions makes code more concise, and still readable
- Scala syntax generally makes function signatures easy to read
- The Scala collections’ classes have a very functional API
- Scala runs on the JVM, so you can still use the wealth of JVM-based libraries and tools with your Scala/FP applications
What’s next
In this chapter I tried to share an honest assessment of the benefits of functional programming. In the next chapter I’ll try to provide an honest assessment of the potential drawbacks and disadvantages of functional programming.
See Also
Quotes in this chapter came from the following sources:
- Real World Haskell
- Clean Code
- Masterminds of Programming
- Scala Cookbook
- The ScalaCheck website
- Property-based-testing on the ScalaTest website
- Functional Programming for the Rest of Us
- Yossi Kreinin’s parallel vs concurrent image
- Joe Armstrong’s parallel vs concurrent article
- The Clojure.org “rationale” page
- Haskell, the Craft of Functional Programming
- Neal Ford’s comments on ibm.com
- Robert C. Martin’s Functional Programming Basics article
- The Downfall of Imperative Programming on fpcomplete.com
- The Erlang website
- The Akka website
- Programming Erlang
- If you want to take a look at OCaml, O’Reilly’s Real World OCaml is freely available online
- “The Trouble with Shared State” section of this medium.com article
- Deterministic algorithms on Wikipedia
- I found John Carmack’s quote in this reprinted article on gamasutra.com
You can also search my alvinalexander.com website for examples of Akka and Scala Futures.