“People say that practicing Zen is difficult,
but there is a misunderstanding as to why.”
| this post is sponsored by my books: | |||

#1 New Release |

FP Best Seller |

Learn Scala 3 |

Learn FP Fast |
In the last chapter I looked at the benefits of functional programming, and as I showed, there are quite a few. In this chapter I’ll look at the potential drawbacks of FP.
Just as I did in the previous chapter, I’ll first cover the “drawbacks of functional programming in general”:
- Writing pure functions is easy, but combining them into a complete application is where things get hard.
- The advanced math terminology (monad, monoid, functor, etc.) makes FP intimidating.
- For many people, recursion doesn’t feel natural.
- Because you can’t mutate existing data, you instead use a pattern that I call, “Update as you copy.”
- Pure functions and I/O don’t really mix.
- Using only immutable values and recursion can potentially lead to performance problems, including RAM use and speed.
After that I’ll look at the more-specific “drawbacks of functional programming in Scala”:
- You can mix FP and OOP styles.
- Scala doesn’t have a standard FP library.
1) Writing pure functions is easy, but combining them into a complete application is where things get hard
Writing a pure function is generally fairly easy. Once you can define your type signature, pure functions are easier to write because of the absence of mutable variables, hidden inputs, hidden state, and I/O. For example, the determinePossiblePlays function in this code:
val possiblePlays = OffensiveCoordinator.determinePossiblePlays(gameState)
is a pure function, and behind it are thousands of lines of other functional code. Writing all of these pure functions took time, but it was never difficult. All of the functions follow the same pattern:
- Data in
- Apply an algorithm (to transform the data)
- Data out
That being said, the part that is hard is, “How do I glue all of these pure functions together in an FP style?” That question can lead to the code I showed in the first chapter:
def updateHealth(delta: Int): Game[Int] = StateT[IO, GameState, Int] { (s: GameState) =>
val newHealth = s.player.health + delta
IO((s.copy(player = s.player.copy(health = newHealth)), newHealth))
}
As you may be aware, when you first start programming in a pure FP style, gluing pure functions together to create a complete FP application is one of the biggest stumbling blocks you’ll encounter. In lessons later in this book I show solutions for how to glue pure functions together into a complete application.
2) Advanced math terminology makes FP intimidating
I don’t know about you, but when I first heard terms like combinator, monoid, monad, and functor, I had no idea what people were talking about. And I’ve been paid to write software since the early-1990s.
As I discuss in the next chapter, terms like this are intimidating, and that “fear factor” becomes a barrier to learning FP.
Because I cover this topic in the next chapter, I won’t write any more about it here.
3) For many people, recursion doesn’t feel natural
One reason I may not have known about those mathematical terms is because my degree is in aerospace engineering, not computer science. Possibly for the same reason, I knew about recursion, but never had to use it. That is, until I became serious about writing pure FP code.
As I wrote in the “What is FP?” chapter, the thing that happens when you use only pure functions and immutable values is that you have to use recursion. In pure FP code you no longer use var fields with for loops, so the only way to loop over elements in a collection is to use recursion.
Fortunately, you can learn how to write recursive code. If there’s a secret to the process, it’s in learning how to “think in recursion.” Once you gain that mindset and see that there are patterns to recursive algorithms, you’ll find that recursion gets much easier, even natural.
Two paragraphs ago I wrote, “the only way to loop over elements in a collection is to use recursion,” but that isn’t 100% true. In addition to gaining a “recursive thinking” mindset, here’s another secret: once you understand the Scala collections’ methods, you won’t need to use recursion as often as you think. In the same way that collections’ methods are replacements for custom for loops, they’re also replacements for many custom recursive algorithms.
As just one example of this, when you first start working with Scala and you have a List like this:
val names = List("chris", "ed", "maurice")
it’s natural to write a for/yield expression like this:
val capNames = for (e <- names) yield e.capitalize
As you’ll see in the upcoming lessons, you can also write a recursive algorithm to solve this problem.
But once you understand Scala’s collections’ methods, you know that the map method is a replacement for those algorithms:
val capNames = fruits.map(_.e.capitalize)
Once you’re comfortable with the collections’ methods, you’ll find that you reach for them before you reach for recursion.
I write much more about recursion and the Scala collections’ methods in upcoming lessons.
4) Because you can’t mutate existing data, you instead use a pattern that I call, “Update as you copy”
For over 20 years I’ve written imperative code where it was easy — and extraordinarily common — to mutate existing data. For instance, once upon a time I had a niece named “Emily Maness”:
val emily = Person("Emily", "Maness")
Then one day she got married and her last name became “Wells”, so it seemed logical to update her last name, like this:
emily.setLastName("Wells")
In FP you don’t do this. You don’t mutate existing objects.
Instead, what you do is (a) you copy an existing object to a new object, and then as a copy of the data is flowing from the old object to the new object, you (b) update any fields you want to change by providing new values for those fields, such as lastName in this example:

The way you “update as you copy” in Scala/FP is with the copy method that comes with case classes. First, you start with a case class:
case class Person (firstName: String, lastName: String)
Then, when your niece is born, you write code like this:
val emily1 = Person("Emily", "Maness")
Later, when she gets married and changes her last name, you write this:
val emily2 = emily1.copy(lastName = "Wells")
After that line of code, emily2.lastName has the value "Wells".
Note: I intentionally use the variable names emily1 and emily2 in this example to make it clear that you never change the original variable. In FP you constantly create intermediate variables like name1 and name2 during the “update as you copy” process, but there are FP techniques that make those intermediate variables transparent.
I show those techniques in upcoming lessons.
“Update as you copy” gets worse with nested objects
The “Update as you copy” technique isn’t too hard when you’re working with this simple Person object, but think about this: What happens when you have nested objects, such as a Family that has a Person who has a Seq[CreditCard], and that person wants to add a new credit card, or update an existing one? (This is like an Amazon Prime member who adds a family member to their account, and that person has one or more credit cards.) Or what if the nesting of objects is even deeper?
In short, this is a real problem that results in some nasty-looking code, and it gets uglier with each nested layer. Fortunately, other FP developers ran into this problem long before I did, and they came up with ways to make this process easier.
I cover this problem and its solution in several lessons later in this book.
5) Pure functions and I/O don’t really mix
As I wrote in the “What is Functional Programming” lesson, a pure function is a function (a) whose output depends only on its input, and (b) has no side effects. Therefore, by definition, any function that deals with these things is impure:
- File I/O
- Database I/O
- Internet I/O
- Any sort of UI/GUI input
- Any function that mutates variables
- Any function that uses “hidden” variables
Given this situation, a great question is, “How can an FP application possibly work without these things?”
The short answer is what I wrote in the Scala Cookbook and in the previous lesson: you write as much of your application’s code in an FP style as you can, and then you write a thin I/O layer around the outside of the FP code, like putting “I/O icing” around an “FP cake”:
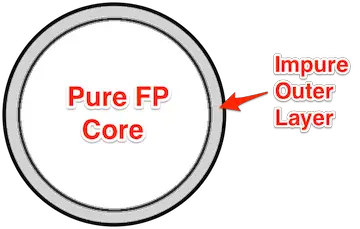
Pure and impure functions
In reality, no programming language is really “pure,” at least not by my definition. (Several FP experts say the same thing.) Wikipedia lists Haskell as a “pure” FP language, and the way Haskell handles I/O equates to this Scala code:
def getCurrentTime(): IO[String] = ???
The short explanation of this code is that Haskell has an IO type that you must use as a wrapper when writing I/O functions. This is enforced by the Haskell compiler.
For example, getLine is a Haskell function that reads a line from STDIN, and returns a type that equates to IO[String] in Scala. Any time a Haskell function returns something wrapped in an IO, like IO[String], that function can only be used in certain places within a Haskell application.
If that sounds hard core and limiting, well, it is. But it turns out to be a good thing.
Some people imply that this IO wrapper makes those functions pure, but in my opinion, this isn’t true. At first I thought I was confused about this — that I didn’t understand something — and then I read this quote from Martin Odersky on scala-lang.org:
“The IO monad does not make a function pure. It just makes it obvious that it’s impure.”
For the moment you can think of an IO instance as being like a Scala Option. More accurately, you can think of it as being an Option that always returns a Some[YourDataTypeHere], such as a Some[Person] or a Some[String].
As you can imagine, just because you wrap a String that you get from the outside world inside of a Some, that doesn’t mean the String won’t vary. For instance, if you prompt me for my name, I might reply “Al” or “Alvin,” and if you prompt my niece for her name, she’ll reply “Emily,” and so on. I think you’ll agree that Some["Al"], Some["Alvin"], and Some["Emily"] are different values.
Therefore, even though (a) the return type of Haskell I/O functions must be wrapped in the IO type, and (b) the Haskell compiler only permits IO types to be in certain places, they are impure functions: they can return a different value each time they are called.
The benefit of Haskell’s IO type
It’s a little early in this book for me to write about all of this, but ... the main benefit of the Haskell IO approach is that it creates a clear separation between (a) pure functions and (b) impure functions. Using Scala to demonstrate what I mean, I can look at this function and know from its signature that it’s pure function:
def foo(a: String): Int = ???
Similarly, when I see that this next function returns something in an IO wrapper, I know from its signature alone that it’s an impure function:
def bar(a: String): IO[String] = ???
That’s actually very cool, and I write more about this in the I/O lessons of this book.
I haven’t discussed UI/GUI input/output in this section, but I discuss it more in the “Should I use FP everywhere?” section that follows.
6) Using only immutable values and recursion can lead to performance problems, including RAM use and speed
An author can get himself into trouble for stating that one programming paradigm can use more memory or be slower than other approaches, so let me begin this section by being very clear:
When you first write a simple (“naive”) FP algorithm, it is possible — just possible — that the immutable values and data-copying I mentioned earlier can be a performance problem.
I demonstrate an example of this problem in a blog post on Scala Quicksort algorithms. In that article I show that the basic (“naive”) recursive quickSort algorithm found in the “Scala By Example” PDF uses about 660 MB of RAM while sorting an array of ten million integers, and is four times slower than using the scala.util.Sorting.quickSort method.
Having said that, it’s important to note how scala.util.Sorting.quickSort works. In Scala 2.12, it passes an Array[Int] directly to java.util.Arrays.sort(int[]). The way that sort method works varies by Java version, but Java 8 calls a sort method in java.util.DualPivotQuicksort. The code in that method (and one other method it calls) is at least 300 lines long, and is much more complex than the simple/naive quickSort algorithm I show.
Therefore, while it’s true that the “simple, naive” quickSort algorithm in the “Scala By Example” PDF has those performance problems, I need to be clear that I’m comparing (a) a very simple algorithm that you might initially write, to (b) a much larger, performance-optimized algorithm.
In summary, while this is a potential problem with simple/naive FP code, I offer solutions to these problems in a lesson titled, “Functional Programming and Performance.”
7) Scala/FP drawback: You can mix FP and OOP styles
If you’re an FP purist, a drawback to using functional programming in Scala is that Scala supports both OOP and FP, and therefore it’s possible to mix the two coding styles in the same code base.
While that is a potential drawback, many years ago I learned of a philosophy called “House Rules” that eliminates this problem. With House Rules, the developers get together and agree on a programming style. Once a consensus is reached, that’s the style that you use. Period.
As a simple example of this, when I owned a computer programming consulting company, the developers wanted a Java coding style that looked like this:
public void doSomething()
{
doX();
doY();
}
As shown, they wanted curly braces on their own lines, and the code was indented four spaces. I doubt that everyone on the team loved that style, but once we agreed on it, that was it.
I think you can use the House Rules philosophy to state what parts of the Scala language your organization will use in your applications. For instance, if you want to use a strict “Pure FP” style, use the rules I set forth in this book. You can always change the rules later, but it’s important to start with something.
8) Scala/FP drawback: Scala doesn’t have a standard FP library
Another potential drawback to functional programming in Scala is that there isn’t a built-in library to support certain FP techniques. For instance, if you want to use an IO data type as a wrapper around your impure Scala/FP functions, there isn’t one built into the standard Scala libraries.
To deal with this problem, independent libraries like Scalaz, Cats, and others have been created. But, while these solutions are built into a language like Haskell, they are standalone libraries in Scala.
I found that this situation makes it more difficult to learn Scala/FP. For instance, you can open any Haskell book and find a discussion of the
IOtype and other built-in language features, but the same is not true for Scala. (I discuss this more in the I/O lessons in this book.)
“Should I use FP everywhere?”
Caution: A problem with releasing a book a few chapters at a time is that the later chapters that you’ll finish writing at some later time can have an impact on earlier content. For this book, that’s the case regarding this section. I have only worked with small examples of Functional Reactive Programming to date, so as I learn more about it, I expect that new knowledge to affect the content in this section. Therefore, a caution: “This section is still under construction, and may change significantly.”
After I listed all of the benefits of functional programming in the previous chapter, I asked the question, “Should I write all of my code in an FP style?” At that time you might have thought, “Of course! This FP stuff sounds great!”
Now that you’ve seen some of the drawbacks of FP, I think I can provide a better answer.
1a) GUIs and Pure FP are not a good fit
The first part of my answer is that I like to write Android apps, and I also enjoy writing Java Swing and JavaFX code, and the interface between (a) those frameworks and (b) your custom code isn’t a great fit for FP.
As one example of what I mean, in an Android football game I work on in my spare time, the OOP game framework I use provides an update method that I’m supposed to override to update the screen:
@Override
public void update(GameView gameView) {
// my custom code here ...
}
Inside that method I have a lot of imperative GUI-drawing code that currently creates this UI:
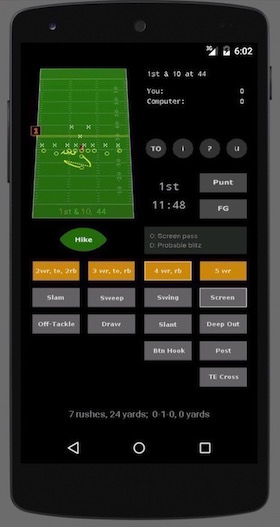
There isn’t a place for FP code at this point. The framework expects me to update the pixels on the screen within this method, and if you’ve ever written anything like a video game, you know that to achieve the best performance — and avoid screen flickering — it’s generally best to update only the pixels that need to be changed. So this really is an “update” method, as opposed to a “completely redraw the screen” method.
Remember, words like “update” and “mutate” are not in the FP vocabulary.
Other “thick client,” GUI frameworks like Swing and JavaFX have similar interfaces, where they are OOP and imperative by design. As another example, I wrote a little text editor that I named “AlPad,” and its major feature is that it lets me easily add and remove tabs to keep little notes organized:

The way you write Swing code like this is that you first create a JTabbedPane:
JTabbedPane tabbedPane = new JTabbedPane();
Once created, you keep that tabbed pane alive for the entire life of the application. Then when you later want to add a new tab, you mutate the JTabbedPane instance like this:
tabbedPane.addTab(
"to-do",
null,
newPanel,
"to-do");
That’s the way thick client code usually works: you create components and then mutate them during the life of the application to create the desired user interface. The same is true for most other Swing components, like JFrame, JList, JTable, etc.
Because these frameworks are OOP and imperative by nature, this interface point is where FP and pure functions typically don’t fit.
If you know about Functional Reactive Programming (FRP), please stand by; I write more on this point shortly.
When you’re working with these frameworks you have to conform to their styles at this interface point, but there’s nothing to keep you from writing the rest of your code in an FP style. In my Android football game I have a function call that looks like this:
val possiblePlays = OffensiveCoordinator.determinePossiblePlays(gameState)
In that code, determinePossiblePlays is a pure function, and behind it are several thousand lines of other pure functions. So while the GUI code has to conform to the Android game framework I’m using, the decision-making portion of my app — the “business logic” — is written in an FP style.
1b) Caveats to what I just wrote
Having stated that, let me add a few caveats.
First, Web applications are completely different than thick client (Swing, JavaFX) applications. In a thick client project, the entire application is typically written in one large codebase that results in a binary executable that users install on their computers. Eclipse, IntelliJ IDEA, and NetBeans are examples of this.
Conversely, the web applications I’ve written in the last few years use (a) one of many JavaScript-based technologies for the UI, and (b) the Play Framework on the server side. With Web applications like this, you have impure data coming into your Scala/Play application through data mappings and REST functions, and you probably also interact with impure database calls and impure network/internet I/O, but just like my football game, the “logic” portion of your application can be written with pure functions.
Second, the concept of Functional-Reactive Programming (FRP) combines FP techniques with GUI programming. The RxJava project includes this description:
“RxJava is a Java VM implementation of Reactive Extensions: a library for composing asynchronous and event-based programs by using observable sequences ... It extends the Observer Pattern to support sequences of data/events and adds operators that allow you to compose sequences together declaratively while abstracting away concerns about things like low-level threading, synchronization, thread-safety and concurrent data structures.”
(Note that declarative programming is the opposite of imperative programming.)
The ReactiveX.io website states:
“ReactiveX is a combination of the best ideas from the Observer pattern, the Iterator pattern, and functional programming.”
I provide some FRP examples later in this book, but this short example from the RxScala website gives you a taste of the concept:
object Transforming extends App {
/**
* Asynchronously calls 'customObservableNonBlocking'
* and defines a chain of operators to apply to the
* callback sequence.
*/
def simpleComposition()
{
AsyncObservable.customObservableNonBlocking()
.drop(10)
.take(5)
.map(stringValue => stringValue + "_xform")
.subscribe(s => println("onNext => " + s))
}
simpleComposition()
}
This code does the following:
- Using an “observable,” it receives a stream of
Stringvalues. Given that stream of values, it ... - Drops the first ten values
- “Takes” the next five values
- Appends the string
"_xform"to the end of each of those five values - Outputs those resulting values with
println
As this example shows, the code that receives the stream of values is written in a functional style, using methods like drop, take, and map, combining them into a chain of calls, one after the other.
I cover FRP in a lesson later in this book, but if you’d like to learn more now, the RxScala project is located here, and Netflix’s “Reactive Programming in the Netflix API with RxJava” blog post is a good start.
This Haskell.org page shows current work on creating GUIs using FRP. (I’m not an expert on these tools, but at the time of this writing, most of these tools appear to be experimental or incomplete.)
2) Pragmatism (the best tool for the job)
I tend to be a pragmatist more than a purist, so when I need to get something done, I want to use the best tool for the job.
For instance, when I first started working with Scala and needed a way to stub out new SBT projects, I wrote a Unix shell script. Because this was for my personal use and I only work on Mac and Unix systems, creating a shell script was by far the simplest way to create a standard set of subdirectories and a build.sbt file.
Conversely, if I also worked on Microsoft Windows systems, or if I had been interested in creating a more robust solution like the Lightbend Activator, I might have written a Scala/FP application, but I didn’t have those motivating factors.
Another way to think about this is instead of asking, “Is FP the right tool for every application I need to write?,” go ahead and ask that question with a different technology. For instance, you can ask, “Should I use Akka actors to write every application?” If you’re familiar with Akka, I think you’ll agree that writing an Akka application to create a few subdirectories and a build.sbt file would be overkill — even though Akka is a terrific tool for other applications.
Summary
In summary, potential drawbacks of functional programming in general are:
- Writing pure functions is easy, but combining them into a complete application is where things get hard.
- The advanced math terminology (monad, monoid, functor, etc.) makes FP intimidating.
- For many people, recursion doesn’t feel natural.
- Because you can’t mutate existing data, you instead use a pattern that I call, “Update as you copy.”
- Pure functions and I/O don’t really mix.
- Using only immutable values and recursion can potentially lead to performance problems, including RAM use and speed.
Potential drawbacks of *functional programming in Scala” are:
- You can mix FP and OOP styles.
- Scala doesn’t have a standard FP library.
| this post is sponsored by my books: | |||
|
#1 New Release |
FP Best Seller |
Learn Scala 3 |
Learn FP Fast |
What’s next
Having covered the benefits and drawbacks of functional programming, in the next chapter I want to help “free your mind,” as Morpheus might say. That chapter is on something I call, “The Great FP Terminology Barrier,” and how to break through that barrier.
See also
- My Scala Quicksort algorithms blog post
- Programming in Scala
- Jesper Nordenberg’s “Haskell vs Scala” post
- Information about my “AlPad” text editor
- “Reactive Extensions” on reactivex.io
- Declarative programming
- Imperative programming
- The RxScala project
- Netflix’s “Reactive Programming in the Netflix API with RxJava” blog post
- Functional Reactive Programming on haskell.org
- Lightbend Activator